Node.js is now the default runtime for new microservices in many enterprise estates. The combination of fast iteration, cheap async I/O, and a large hiring pool is hard to beat for product backends. But microservices break in expensive ways when teams skip the patterns that hold them together. This guide is what we recommend to engineering leaders building or rescuing a Node.js microservices estate in 2026.
If you need engineers who can build this for you, see our Node.js hiring page or read the role of a Node.js developer in enterprise applications.
When should you actually use microservices?
Most enterprise teams reach for microservices too early. The honest test:
- Multiple teams shipping independently. If one team owns the codebase, you do not need microservices. You need clean modules.
- Different scaling profiles per service. A search service and a billing service have nothing in common operationally. Splitting them is justified.
- Different runtime needs. One service needs a GPU, another needs a long-running connection pool. Splitting earns its keep.
- Compliance or tenancy boundaries. A PCI-scoped service should not share a process with a marketing-tracking service.
If none of these apply, build a modular monolith. NestJS modules give you most of the benefits of service boundaries without the operational tax. You can split later when the boundaries prove themselves.
Which framework should you build on?
For new enterprise microservices in Node.js, the practical shortlist is NestJS, Fastify, or a thin Express baseline. We recommend:
| Framework | Best for | Why it wins |
|---|---|---|
| NestJS | Most enterprise services | Modular DI container, decorator-driven contracts, first-class TypeScript, strong gRPC and microservice transports built in |
| Fastify | High-throughput APIs | Lower overhead per request, schema-first JSON validation, plugin architecture that scales |
| Express | Legacy services and BFFs | Universal familiarity, minimal lock-in, easy to migrate from in either direction |
Most teams we work with default to NestJS for new domain services and use Fastify only when latency or throughput targets demand it.
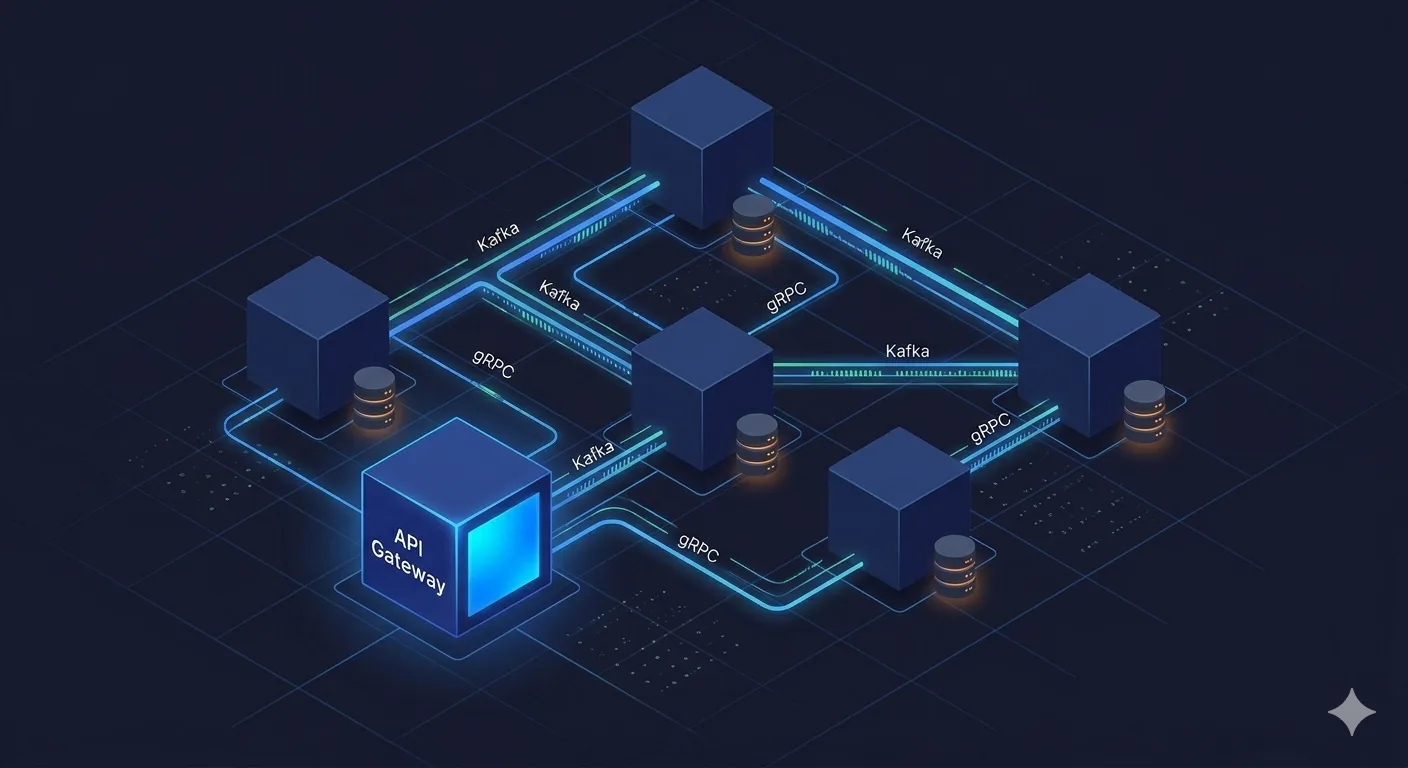
How should services communicate?
Pick the transport per interaction shape, not per service:
- gRPC for synchronous service-to-service calls. Strong typing through protobuf, low overhead, bidirectional streaming for real-time. NestJS has first-class support.
- REST or GraphQL for external and BFF traffic. Both are fine. GraphQL earns its keep when multiple frontends need different shapes of the same data.
- Message queues for async work. Kafka for high-throughput event streams, SQS or RabbitMQ for job queues, BullMQ for in-house background work backed by Redis.
- Event buses for fan-out. Kafka, SNS, or NATS when one event needs to land in many services without point-to-point coupling.
The anti-pattern is synchronous HTTP chains across more than three services. Every hop adds latency, every hop is a failure point, and the resulting blast radius surprises teams in the first real incident.
How should each service own its data?
The single most important rule: each service owns its database. No cross-service joins. No shared schemas. If service A needs data from service B, it asks via API or it consumes events.
Concrete patterns that hold up:
- One database per service, isolated network. PostgreSQL most commonly, MongoDB where document fit is real, Redis for caches and queues.
- Migrations in the service repo. Prisma, Drizzle, or TypeORM with migration files committed alongside code.
- Outbox pattern for reliable events. Write to your DB and an outbox table in the same transaction, then a worker publishes to Kafka. This avoids "the DB committed but the event was lost."
- Sagas for cross-service workflows. When a flow spans services, model it as a saga with explicit compensations. Do not try to fake distributed transactions.
- Read models for query needs. Build per-service materialized views that consume events from other services, instead of cross-service joins.
How do you handle failures across services?
Microservices fail differently from monoliths. The patterns that matter:
- Timeouts on every call. Default to short timeouts (500ms to 2s) and tune up only with evidence.
- Retries with jitter. Exponential backoff plus jitter, and only on idempotent operations. Retrying a non-idempotent payment is how you bill twice.
- Circuit breakers. Open the circuit when downstream errors spike, fail fast, and shed load instead of cascading.
- Bulkheads. Separate connection pools, thread pools, and queues per downstream so one slow dependency cannot starve the rest.
- Idempotency keys on writes. Every write endpoint accepts an Idempotency-Key header so retries do not duplicate side effects.
- Dead letter queues. Failed messages go to a DLQ, not into the void. Operators get an alert and a path to replay.
How do you observe a Node.js microservices estate?
You cannot debug what you cannot see. The minimum bar for production:
- Structured logging with pino or Winston, JSON output, request IDs, correlation IDs, and tenant IDs on every line.
- Distributed tracing with OpenTelemetry, instrumented at the framework level (NestJS interceptors or Fastify hooks) so every request gets a trace.
- Metrics with Prometheus or Datadog: RPS, error rate, p50, p95, p99 latency per endpoint, plus runtime metrics like event loop lag.
- Per-service SLOs with explicit error budgets, not vanity uptime numbers.
- On-call runbooks with the top 5 failure modes and the first 3 commands to run for each.
Event loop lag is the single most useful Node.js-specific metric. When it spikes, every request on that pod gets slow. Alarms on event loop lag catch problems before users do. For more on Node.js performance specifically, see our performance and scaling checklist.
How do you secure a Node.js microservices estate?
Three layers, all of them required:
- Network: mutual TLS between services, network policies in Kubernetes, no public ingress to internal services.
- Identity: short-lived JWTs or workload identity (SPIFFE/SPIRE), with a central authorization service for permission decisions.
- Application: input validation with zod or class-validator on every endpoint, OWASP-aligned controls, dependency scanning on every CI run.
The deeper Node.js-specific security surface is in our Node.js security checklist.
How should you deploy and operate?
For most enterprise Node.js microservices in 2026, deployment looks like:
- Docker images built with multi-stage builds, distroless or alpine base, non-root user.
- Kubernetes for general workloads, with HPA on RPS or CPU, PDBs for graceful draining, readiness probes that check downstream health.
- Serverless (Lambda, Cloud Run) for spiky or low-volume services where cold starts are tolerable. Bundle with esbuild for small artifacts.
- Service mesh (Istio, Linkerd) only when retries, mTLS, and observability cannot be solved at the framework layer. Many teams skip the mesh entirely.
- CI/CD on GitHub Actions or GitLab, with automated test, lint, type check, dependency scan, container scan, and progressive deployment.
What are the most common mistakes we see?
From our placement work in 2025 and 2026:
- Splitting too early. Three services that should have been one module, with HTTP between them and a shared DB underneath. The worst of both worlds.
- Shared database across services. Coupling masquerading as decoupling. Every schema change becomes a multi-team coordination problem.
- Sync chains for everything. Service A calls B calls C calls D. One slow downstream takes the whole chain down.
- No event loop lag alarms. Engineers wonder why p99 spikes during cron runs. The answer is always a CPU-bound function blocking the loop.
- Missing idempotency. Retries duplicate side effects. The team learns this in a billing incident.
- Ignoring npm supply chain. One typosquatted dependency lands in a build. The team learns this in a security incident.
Where does Workforce Next help?
We place Node.js engineers who have shipped microservices in production at enterprise scale. Most have built or rescued NestJS estates, set up gRPC and Kafka pipelines, and run on Kubernetes or serverless in production for years. If you want to staff a microservices initiative, see our Node.js hiring page or talk to us about your architecture.