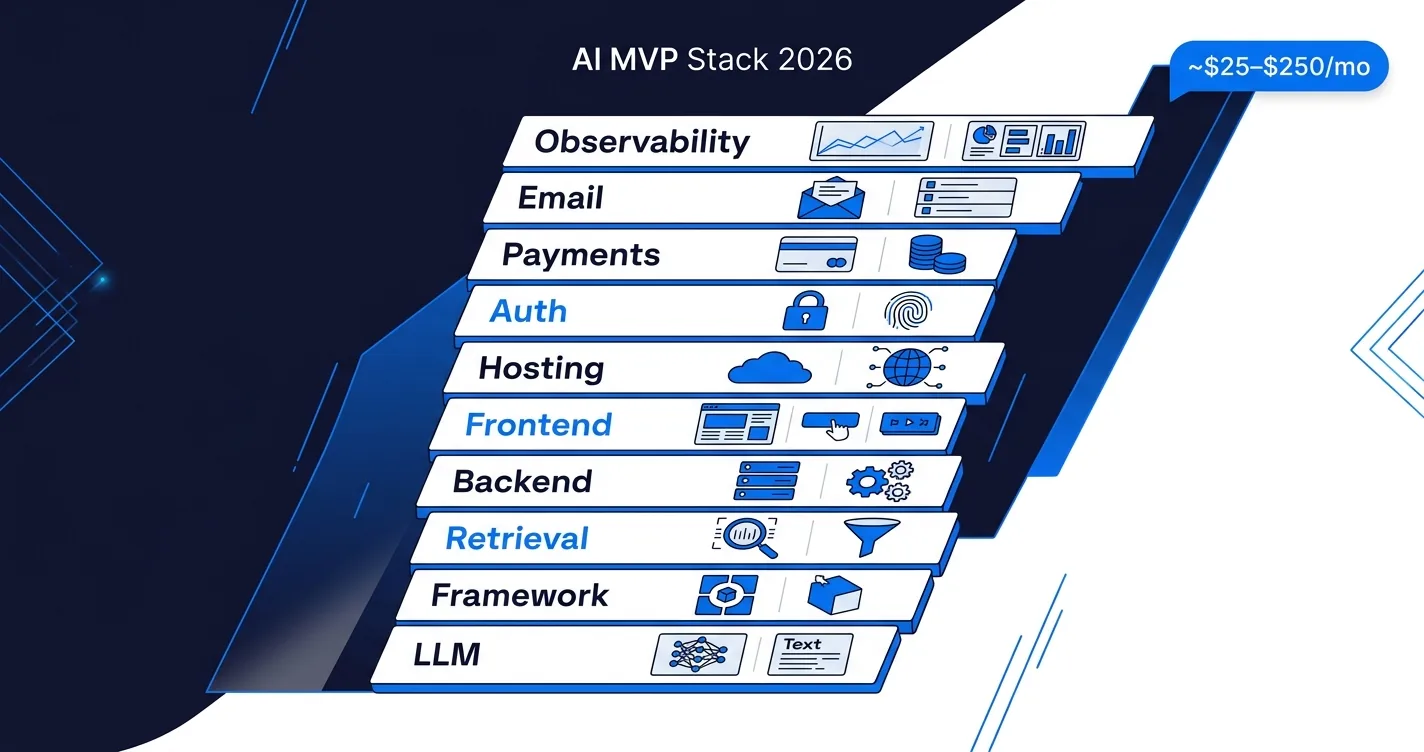
The shortest answer: pick boring, battle-tested services for everything except the AI feature itself. Use Clerk for auth, Resend for email, Stripe for payments, Supabase or Neon for Postgres, pgvector for retrieval, Vercel or Railway for hosting, and the Anthropic or OpenAI SDK directly without a framework. That stack ships a working AI MVP in 4 weeks for roughly $25 to $250 a month of infra and third-party fees, leaving all your engineering time for the thing that actually makes your product different.
This post is the tool-by-tool guide we actually use when building 4-week AI MVPs for clients. If you have not yet read the week-by-week breakdown, see how to build an AI MVP in 4 weeks with one offshore developer first. This post is the companion stack reference.
What belongs in an AI MVP stack, and what does not?
Three principles govern every stack choice:
1. Do not build anything a $20/month SaaS solves. Auth, payments, email, file uploads, logs. If you can rent it for under $50 a month in month one, rent it. You can build your own later when you have revenue and time.
2. Own the AI layer. This is the only place in the stack where custom engineering earns its keep. Prompts, retrieval logic, eval sets, and model selection are where your product differentiates. Do not rent your way out of the thing users are paying for.
3. Pick tools that scale 10x without migration. You will outgrow some pieces eventually, but an MVP should not force a rewrite in month four. Favor tools with a paid tier that covers the first year of likely growth.
Everything below follows from these three rules.
Which LLM provider do you pick for an MVP?
Three serious options in 2026: Claude (Anthropic), GPT-class (OpenAI), and Gemini (Google). Honest tradeoffs:
Claude. Best out-of-the-box instruction following, strongest for long-form reasoning and document work, clean tool use, generous context windows. Our default for most MVP work unless there is a reason to pick otherwise.
OpenAI. Largest ecosystem of tooling and community examples, strong structured output, cheapest at the small-model tier. Pick when your team has existing GPT experience or you need the breadth of third-party integrations.
Gemini. Best native multimodal support (image, video, audio), strong for long-context retrieval, competitive pricing at scale. Pick when multimodal is central to your product.
Pragmatic MVP move: build against an abstraction layer (the OpenAI SDK shape works for most providers, or use an AI gateway like Vercel AI Gateway or OpenRouter) so switching providers is a config change, not a rewrite. Do not spend week one agonizing over the choice.
LangChain, LlamaIndex, or no framework at all?
For an MVP, default to no framework. Write against the provider SDK directly (Anthropic SDK or OpenAI SDK). Tool calling, structured output, and streaming are native in every major model API now. You will ship faster and debug faster without the indirection.
Reach for LangChain/LangGraph when your workflow has real multi-step state or you need the broad integration ecosystem. Reach for LlamaIndex when retrieval is the dominant workload and default chunking and search quality matters more than the rest of the stack. Full decision framework in our guide on how to choose an AI agent framework.
The one scenario where a framework is obviously right at MVP stage: a research-assistant or multi-specialist pipeline that maps cleanly to CrewAI-style agent teams. Most MVPs are not this.
What do you use for retrieval and vector search?
Default at MVP scale: pgvector on your existing Postgres. If you already have Supabase or Neon, you already have pgvector. One less service to manage, good enough to 100k+ embedded chunks with decent indexing, and you can migrate to a dedicated vector DB later if retrieval becomes the real bottleneck.
Pick a dedicated vector DB (Pinecone, Qdrant, Weaviate) when:
- Your corpus is already above 1M embedded chunks in week one.
- You need advanced features like hybrid search with built-in reranking.
- You are running multi-tenant retrieval with strict namespacing.
Qdrant self-hosted on a $20/month VPS is our pick when pgvector is not enough but Pinecone's minimum bill feels premature. See our RAG vs fine-tuning guide if you are not sure retrieval is the right approach at all.
What about the backend, frontend, and hosting?
Opinionated defaults that ship fast:
Backend. FastAPI (Python) if your team is Python-heavy or your AI pipeline is Python-native. Next.js API routes or Hono (TypeScript) if your team is TypeScript-heavy and you want one repo for everything. Both ship 4-week MVPs fine.
Frontend. Next.js is the default. App Router, Server Components, Tailwind, shadcn/ui. It covers auth, SEO, streaming AI responses, and hosting on Vercel in one coherent stack. Vite plus React is a fine alternative for SPA-style apps without SSR needs.
Hosting. Vercel for Next.js apps (zero-config deploys, great DX, cost-effective up to roughly $100 a month). Railway or Fly for FastAPI backends (Dockerized, $5 to $30 a month, no vendor lock). AWS or GCP only if you have a compliance or existing-infra reason to. For the workflow-automation layer, our 2026 comparison of n8n, Zapier, Step Functions, and others covers that decision separately.
Our fullstack developers ship this shape of stack in 4-week sprints routinely. The key is not fighting the stack: pick the defaults and ship the product.
How do you skip building auth, payments, and email?
Three SaaS categories that should never be custom in an MVP:
Auth. Clerk is the fastest by a wide margin. Drop-in UI, social logins, multi-factor, org support, and reasonable pricing up to 10k monthly active users. Supabase Auth is a fine alternative if you are already on Supabase. Auth.js (next-auth) for more control, but it will cost you a day or two of setup you probably do not have.
Payments. Stripe for subscription and usage billing. Paddle or Lemon Squeezy if you want a merchant-of-record setup (they handle VAT and sales tax globally). Integrating any of these takes under a day, building your own is weeks of PCI-adjacent pain.
Transactional email. Resend is our default: clean API, React email templates, generous free tier. Postmark for deliverability-critical use cases (password resets, receipts). AWS SES if you already run AWS heavily and want the lowest per-email cost.
Combined cost at MVP stage: under $50 a month for all three, probably under $20 if you are on free tiers.
What observability is worth the setup time at MVP stage?
Most observability tools are overkill for an MVP. The three that are worth the setup time on day one:
LLM observability. Langfuse (open source, self-hosted or cloud) or Helicone. Both let you see every prompt, response, latency, and cost per request without custom instrumentation. Setup takes 15 minutes and pays for itself the first time a prompt misbehaves in production.
Application errors. Sentry free tier. Ten minutes of setup, covers frontend and backend, catches what users would have otherwise silently rage-quit over.
Basic analytics. Vercel Analytics if you are on Vercel, PostHog if you want product analytics (event tracking, funnels) on the free tier.
Skip: OpenTelemetry (too much setup work for MVP), Datadog (too expensive), custom dashboards (you will not look at them).
How do costs add up for a typical 4-week MVP?
Rough month-one total for a typical AI MVP on the stack above:
| Category | Tool | Typical MVP cost/month |
|---|---|---|
| LLM provider | Claude or GPT-class | $20 to $150 (eval + early user volume) |
| Backend hosting | Railway or Fly | $5 to $30 |
| Frontend hosting | Vercel | $0 to $20 (Hobby or Pro start) |
| Database | Supabase or Neon | $0 to $25 |
| Vector DB | pgvector (in Postgres) or Qdrant VPS | $0 (included) or $20 |
| Auth | Clerk | $0 (free tier covers MVP) |
| Payments | Stripe | $0 + 2.9% per txn |
| Resend | $0 (free 3k emails/mo) | |
| LLM observability | Langfuse Cloud | $0 (free tier) |
| Error tracking | Sentry free | $0 |
| Total | ~$25 to $250/mo |
LLM spend is the only line that scales unpredictably with usage. The rest is effectively fixed-cost through the first 1,000 users. Build the product, then optimize.
What should you skip entirely at MVP stage?
Common traps that add weeks with no product benefit:
- Custom auth. Seriously, never.
- Fine-tuning a model. Start with prompt engineering and retrieval. See our RAG vs fine-tuning decision tree.
- Building your own observability or eval platform. Langfuse gets you 90 percent of what you need.
- Kubernetes. Vercel, Railway, and Fly handle all the container and orchestration work. You do not need K8s for an MVP.
- Microservices. One service, one database, one repo. Split later if you actually need to.
- A CI/CD pipeline beyond "git push". Vercel and Railway both auto-deploy on push. Add GitHub Actions only when tests are slow enough to need it.
- Custom admin panel. Retool or Supabase's built-in dashboard cover 90 percent of ops needs in month one.
- A dedicated prompt engineer on day one. See our guide on whether you still need a prompt engineer in 2026. For an MVP, one AI developer who prompt-engineers as part of the job is the right shape.
The shortest version
Pick boring for everything except the AI feature. Clerk for auth, Stripe for payments, Resend for email, Supabase or Neon for Postgres, pgvector for retrieval, Vercel or Railway for hosting, the Anthropic or OpenAI SDK directly (no framework), Langfuse for LLM observability, Sentry for errors. Total infra under $250 a month for a typical MVP through the first thousand users. If you want a developer who already ships this stack in 4-week sprints, our fullstack engineers and AI developers have done this across dozens of MVPs. Get in touch and we will scope your build.